Dynamic Programming and Bellman Optimality Principle
Dynamic programming provides a systematic approach to solving optimal control problems by decomposing complex problems into simpler subproblems. This document introduces the fundamental concepts and demonstrates the method through a practical drone control example.
Bellman Optimality Principle
The Bellman Optimality Principle states:
"An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision."
Key insights:
- Universal principle: Applies regardless of initial state and decision
- Optimal substructure: Remaining decisions must be optimal for the resulting state
- Foundation for dynamic programming: Enables backward recursive solution
Dynamic programming is a computational method that applies the Bellman optimality principle to solve optimal control problems efficiently by avoiding redundant calculations through systematic storage and reuse of subproblem solutions.
Problem Setup: Drone Vertical Movement
System Model
Consider a simple drone moving vertically with the following dynamics:
State-space representation:
State vector:
Where:
- : position (height) of drone
- : velocity of drone
Problem Parameters
Initial state:
Target state:
Constraints:
- Input constraint:
- Velocity constraint:
Objective (minimum time):
State Space Discretization
To apply dynamic programming, we discretize the continuous state space into a finite grid.
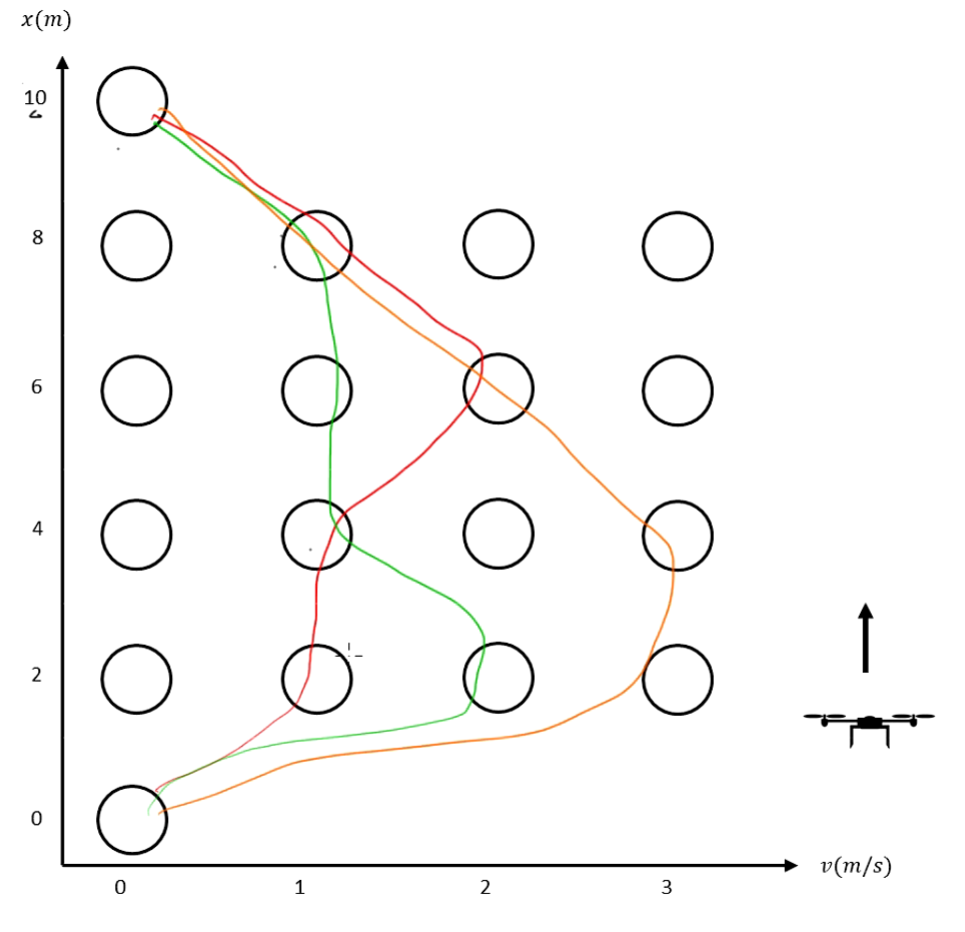
Discretization scheme:
- Height (): 5 intervals → 6 nodes
- Velocity (): 3 intervals → 4 nodes
- Total states: nodes
The discretized system satisfies the Markov property: the future state depends only on the current state and action, not on the history of states.
Solution Approaches Comparison
Brute Force Search (Exhaustive Method)
Computational complexity:
Characteristics:
- ✅ Guarantees global optimum
- ❌ Exponential computational complexity
- ❌ Becomes intractable for large state spaces
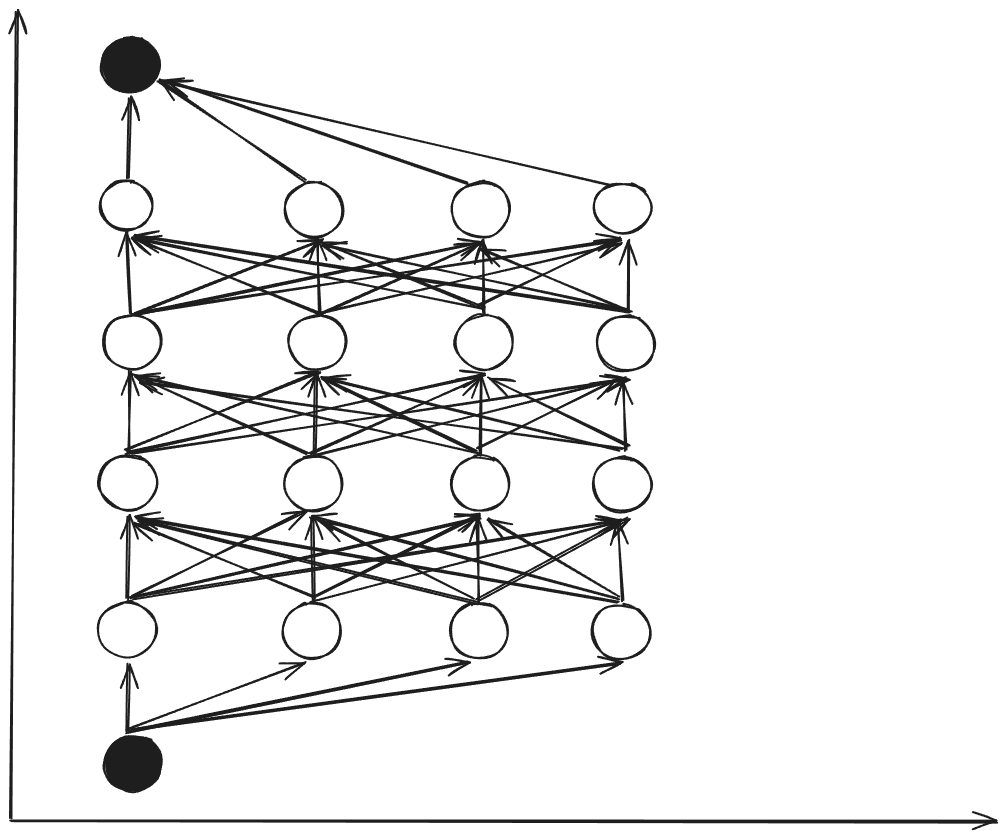
Dynamic Programming (Backward Multi-stage)
Computational complexity:
Characteristics:
- ✅ Polynomial computational complexity
- ✅ Systematic and optimal
- ✅ Enables offline computation of control policy
Dynamic Programming Algorithm
Step 1: Dynamics Equations
Average velocity between nodes:
Time between nodes:
Required input:
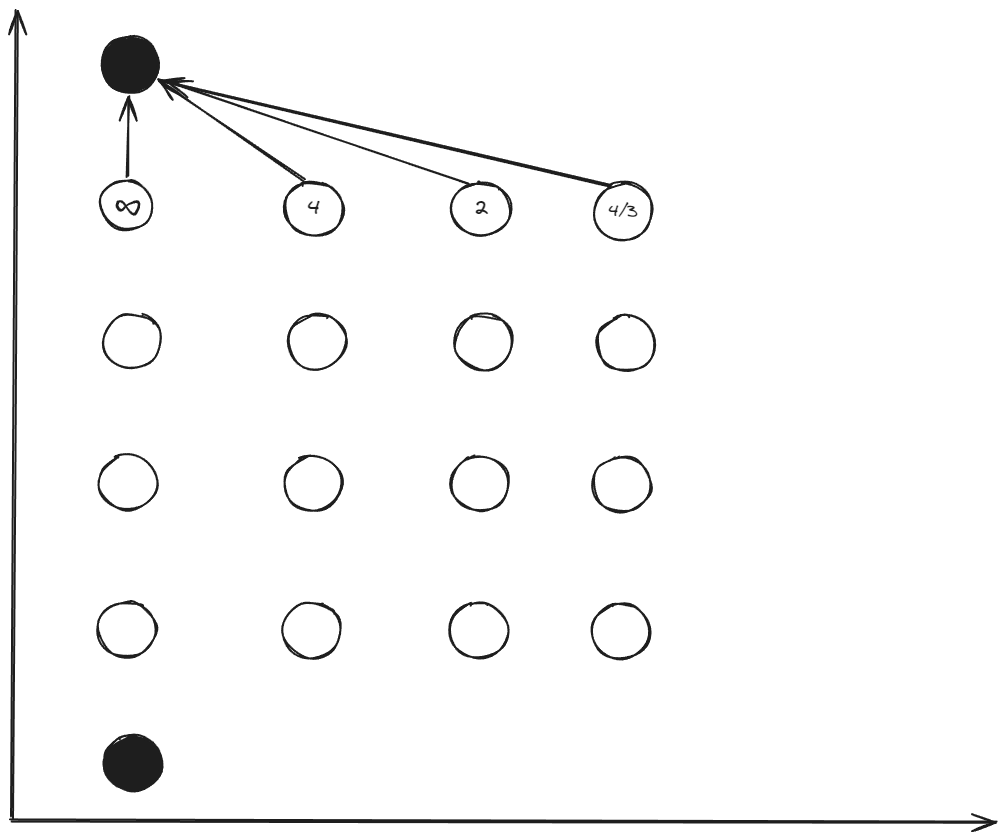
Step 2: Backward Recursion ()
Starting from the final stage:
Calculate transitions:
For :
For :
For :
For :
Cost-to-go values:
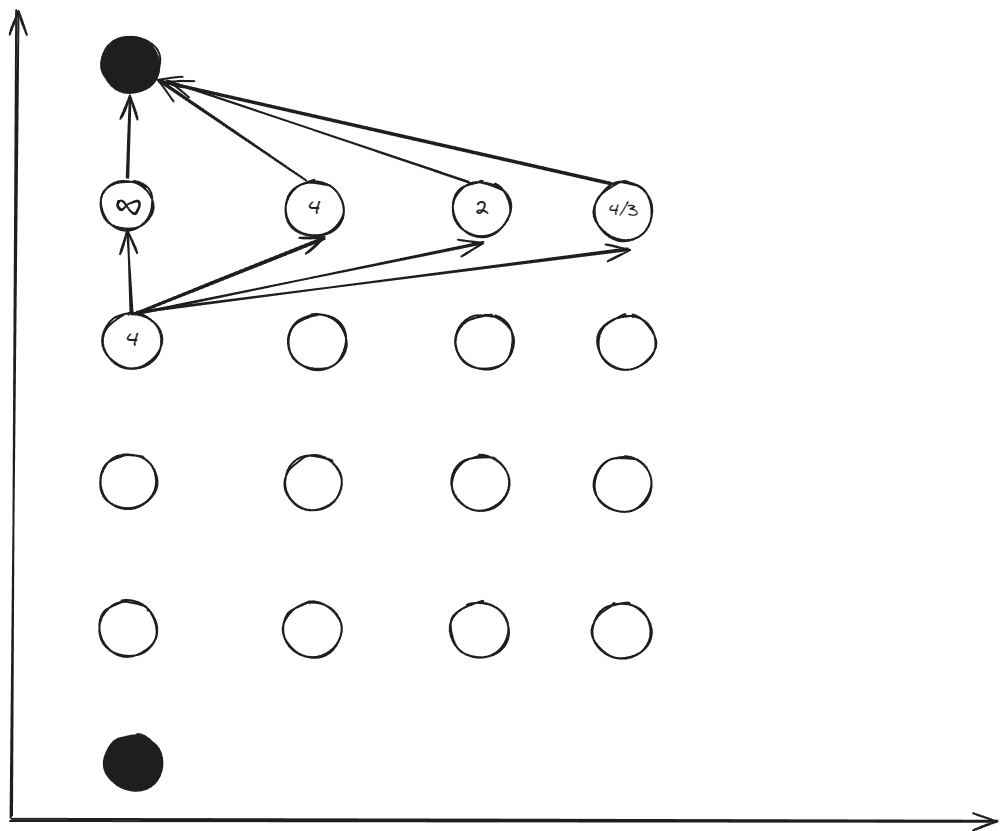
Step 3: Continue Backward ()
For each node at stage 4, evaluate all possible transitions to stage 5.
Example for :
Evaluate transitions to all stage 5 nodes:
- : (infeasible)
- : ,
- : ,
- : , (violates constraint)
Optimal choice: with total cost:
Step 4: Complete Backward Calculation
Continue this process for all stages until reaching the initial state.
Final cost-to-go table:
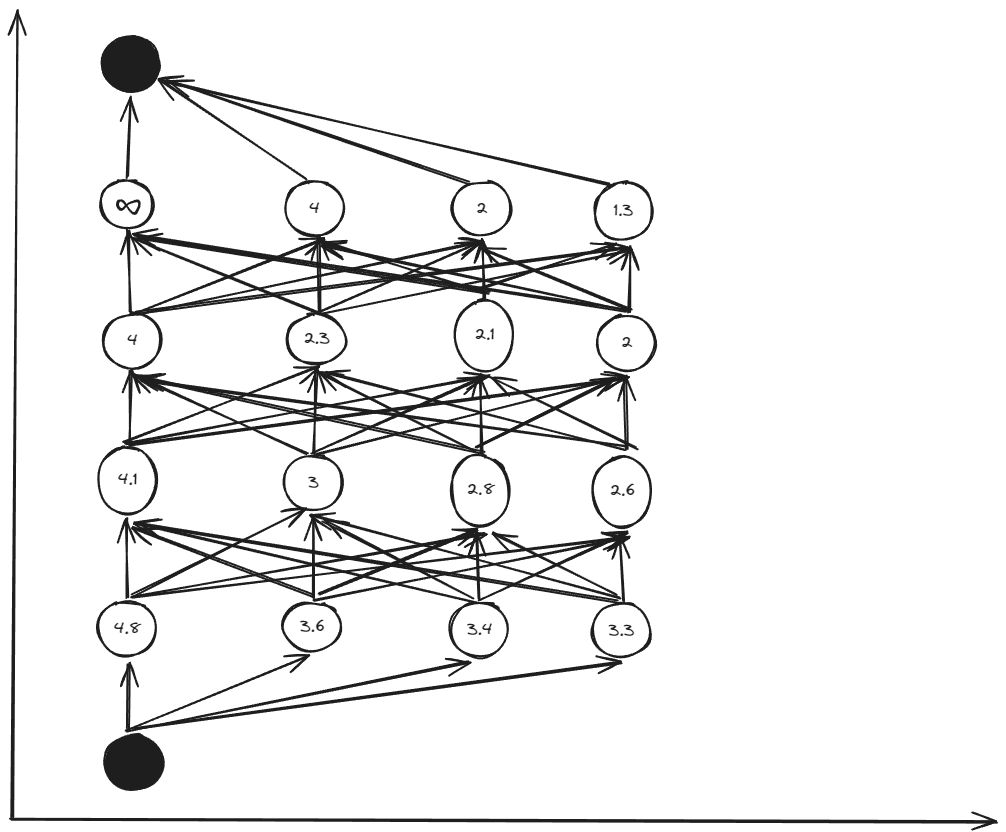
Optimal control policy table:
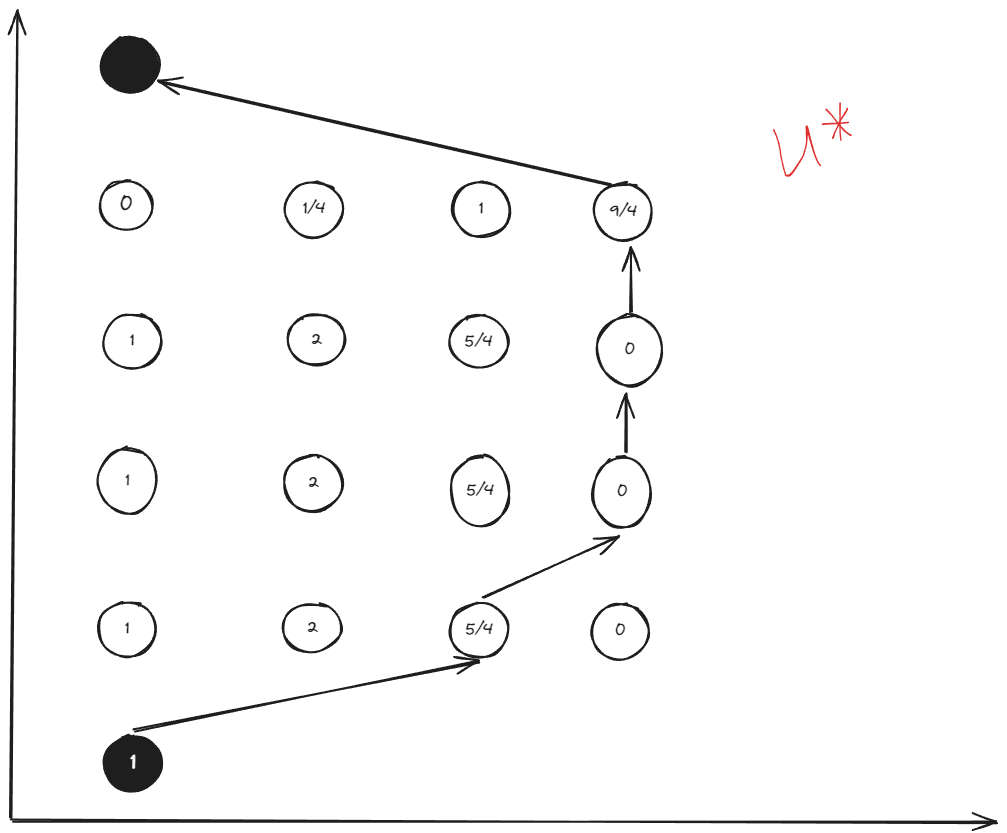
Key Advantages of Dynamic Programming
1. Computational Efficiency
- Brute force: exponential complexity
- Dynamic programming: polynomial complexity
2. Optimal Substructure
At each stage , we compute all possible actions for each node but retain only the optimal result. This satisfies the Bellman principle: whatever happened before, the optimal path from the current node to the end has been determined.
3. Offline Computation
The entire control policy can be computed offline and stored in lookup tables for real-time implementation.
MATLAB Implementation
clear; close all;
set(0,'DefaultAxesFontName','Times New Roman')
set(0,'DefaultAxesFontSize',22)
% Problem parameters
h_init = 0; v_init = 0;
h_final = 10; v_final = 0;
h_min = 0; h_max = 10; N_h = 5;
v_min = 0; v_max = 3; N_v = 3;
u_min = -3; u_max = 2;
% Create state arrays
Hd = h_min:(h_max-h_min)/N_h:h_max;
Vd = v_min:(v_max-v_min)/N_v:v_max;
% Initialize cost-to-go and input matrices
J_costtogo = zeros(N_h+1, N_v+1);
Input_acc = zeros(N_h+1, N_v+1);
% Backward dynamic programming
for k = 2:N_h
if k == 2
% Final stage: transition to target
v_avg = 0.5*(v_final + Vd);
T_delta = (h_max-h_min)./(N_h * v_avg);
acc = (0 - Vd)./T_delta;
else
% Intermediate stages
[Vd_x, Vd_y] = meshgrid(Vd, Vd);
v_avg = 0.5*(Vd_x + Vd_y);
T_delta = (h_max-h_min)./(N_h * v_avg);
acc = (Vd_y - Vd_x)./T_delta;
end
% Apply constraints
J_temp = T_delta;
[acc_x, acc_y] = find(acc < u_min | acc > u_max);
J_temp(sub2ind(size(acc), acc_x, acc_y)) = inf;
if k > 2
J_temp = J_temp + meshgrid(J_costtogo(k-1,:))';
[J_costtogo(k,:), l] = min(J_temp);
Input_acc(k,:) = acc(sub2ind(size(J_temp), l, 1:length(l)));
else
J_costtogo(k,:) = J_temp;
Input_acc(k,:) = acc;
end
end
% Forward simulation using optimal policy
h_plot = zeros(N_h+1,1); v_plot = zeros(N_h+1,1); acc_plot = zeros(N_h,1);
h_plot(1) = h_init; v_plot(1) = v_init;
for k = 1:N_h
[~, h_idx] = min(abs(h_plot(k) - Hd));
[~, v_idx] = min(abs(v_plot(k) - Vd));
acc_plot(k) = Input_acc(N_h+2-h_idx, v_idx);
v_plot(k+1) = sqrt(2*(h_max-h_min)/N_h*acc_plot(k) + v_plot(k)^2);
h_plot(k+1) = h_plot(k) + (h_max-h_min)/N_h;
end
% Plot results
figure;
plot(v_plot, h_plot, '--^', 'LineWidth', 2, 'MarkerSize', 8);
grid on; xlabel('Velocity (m/s)'); ylabel('Height (m)');
title('Optimal Trajectory');
Simulation Results
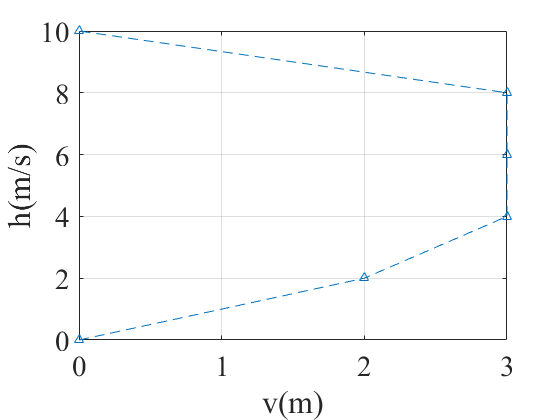
The optimal trajectory shows the drone accelerating initially to gain speed, then decelerating to reach zero velocity at the target height, all while respecting the input and state constraints.
Advantages and Limitations
Advantages
- Guaranteed optimality for the discretized problem
- Polynomial complexity vs. exponential brute force
- Offline computation enables real-time implementation
- Handles constraints naturally
- Provides complete policy for all states
Limitations
- Curse of dimensionality: Exponential growth with state dimension
- Discretization errors: Approximate solution for continuous problems
- Memory requirements: Must store value function/policy
- Fixed grid: May miss optimal continuous solutions
Extensions and Applications
1. Stochastic Dynamic Programming
Handle uncertain dynamics and disturbances by considering expected costs.
2. Approximate Dynamic Programming
Use function approximation to handle high-dimensional problems.
3. Real-time Applications
- Model Predictive Control: Apply DP in receding horizon
- Reinforcement Learning: Learn value functions through experience
- Game Theory: Multi-agent optimal control
References
- Optimal Control by DR_CAN
- Wang, T. (2023). 控制之美 (卷2). Tsinghua University Press.
- Rakovic, S. V., & Levine, W. S. (2018). Handbook of Model Predictive Control.
- Bellman, R. (1957). Dynamic Programming. Princeton University Press.
- Bertsekas, D. P. (2017). Dynamic Programming and Optimal Control (4th ed.). Athena Scientific.