ベイズ推定 (Bayesian Inference)
線形回帰におけるベイズ推定手法について学習します。観測データが逐次得られる環境において、事前分布を事後分布に更新していく逐次ベイズ学習の理論と実装を詳しく解説します。
概要
ベイズ推定は、観測データを基に未知パラメータの確率分布を更新する統計的手法です。古典的な最小二乗法とは異なり、パラメータを確率変数として扱い、不確実性を定量化できる重要な手法です。
主な特徴
- 逐次更新:新しい観測データが得られるたびにパラメータ分布を更新
- 不確実性の定量化:パラメータの分散を通じて推定の信頼性を評価
- 事前知識の活用:事前分布により既知の情報を組み込み可能
- 計算効率:オンライン学習が可能で、大規模データに適用可能
問題設定
1. 基本問題
観測データ が得られたとき、この観測結果を直線 に回帰します。回帰直線のパラメータ と を逐次ベイズ学習により推定し、その結果を考察します。
手順1:観測データの生成
- から を一様乱数により生成
- に従って から を生成
- :適当な真値を設定
- :平均0、分散の正規乱数(ノイズ)
手順2:逐次ベイズ学習による推定
- 事前分布のパラメータを設定
- が得られるたびに更新式に従ってパラメータ更新を実行
ノイズの標準偏差が のとき、精度パラメータは:
また、以下の関係が重要です:
- (正則化定数)
理論的背景
2.1 観測モデル
一般的な線形回帰モデルは以下のように表現されます:
これを行列形式で表現すると:
ここで:
設計行列 は:
2.2 確率分布の設定
ベイズ線形回帰では、以下の正規分布を仮定します:
事前分布(事前データなし):
尤度(観測分布):
パラメータ設定:
ノイズモデル:
- が小さい:事前分布の分散 が大きくなり、事前情報への信頼度が低い
- が小さい:観測分布の分散 が大きくなり、観測ノイズが大きい
- :正則化の強さを制御するパラメータ
2.3 ベイズ推定解
事後分布:
精度行列:
MMSE推定解:
この解は、平均二乗誤差を最小化する最適推定値となります。
実装とシミュレーション
3.1 必要なライブラリのインポート
# 基本ライブラリ
import numpy as np
import scipy as sp
import pandas as pd
from pandas import Series, DataFrame
from scipy.stats import multivariate_normal
# 可視化ライブラリ
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.mlab as mlab
import seaborn as sns
# 設定
np.set_printoptions(precision=3)
plt.style.use('seaborn-v0_8')
3.2 可視化関数の定義
def plot_data(ax, x_min, x_max, x, y, x_seq, mu):
"""
観測データと回帰直線の描画関数
Parameters:
-----------
ax : matplotlib.axes
描画対象の軸
x_min, x_max : float
x軸の範囲
x, y : array-like
観測データ
x_seq : array-like
回帰直線描画用のx座標
mu : array-like
推定されたパラメータ [θ₀, θ₁]
"""
ax.set_xlim(x_min, x_max)
ax.set_ylim(x_min, x_max)
ax.scatter(x, y, color='blue', alpha=0.7, s=30)
ax.plot(x_seq, mu[0] + mu[1] * x_seq, color='red', linewidth=2)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.grid(True, alpha=0.3)
def plot_heatmap(ax, x_min, x_max, rv, x_seq, y_seq, pos):
"""
事後分布の表示関数(ヒートマップ)
Parameters:
-----------
ax : matplotlib.axes
描画対象の軸
x_min, x_max : float
軸の範囲
rv : scipy.stats.multivariate_normal
多変量正規分布オブジェクト
x_seq, y_seq : array-like
メッシュグリッド座標
pos : array-like
位置座標配列
"""
ax.set_xlim(x_min, x_max)
ax.set_ylim(x_min, x_max)
contour = ax.contourf(x_seq, y_seq, rv.pdf(pos), levels=20, cmap='viridis', alpha=0.8)
ax.set_xlabel('θ₀')
ax.set_ylabel('θ₁')
ax.grid(True, alpha=0.3)
return contour
3.3 観測データの生成
# シミュレーション条件の設定
np.random.seed(0) # 再現性のためのランダムシード固定
c = np.array([-0.3, 0.5]) # パラメータの真値 [θ₀, θ₁]
sigma = 0.2 # ノイズの標準偏差
alpha = 0.1 # 事前分布の精度パラメータ
beta = 1.0 / (sigma ** 2) # ノイズの精度パラメータ
gzai = alpha / beta # 正則化定数
mu = np.zeros(2) # 事前分布の平均値ベクトル
Gamma = alpha * np.identity(2) # 事前分布の精度行列
inv_Gamma = np.linalg.inv(Gamma) # 事前分布の共分散行列
M = 50 # サンプル数
# 描画設定
x_min, x_max = -1.0, 1.0 # x軸の描画範囲
y_min, y_max = -1.0, 1.0 # y軸の描画範囲
# 観測データの生成
# ノイズ生成
e = np.random.normal(0, sigma, M)
# 観測データx の生成(一様分布)
x = np.random.uniform(x_min, x_max, M)
# 観測データy の生成(線形関係 + ノイズ)
y = c[0] + c[1] * x + e
print(f"真のパラメータ: θ₀ = {c[0]:.3f}, θ₁ = {c[1]:.3f}")
print(f"ノイズ標準偏差: σ = {sigma:.3f}")
print(f"精度パラメータ: α = {alpha:.3f}, β = {beta:.3f}")
print(f"正則化定数: ξ = {gzai:.3f}")
print(f"S/N比: {np.std(c[0] + c[1] * x) / sigma:.3f}")
3.4 逐次ベイズ学習の実行
# 描画設定
fig = plt.figure(figsize=(15, 8 * M))
x_seq, y_seq = np.mgrid[x_min:x_max:.01, y_min:y_max:.01] # メッシュグリッド作成
pos = np.empty(x_seq.shape + (2,))
pos[:, :, 0] = x_seq
pos[:, :, 1] = y_seq
# 初期分布の設定
rv = multivariate_normal(mu, inv_Gamma)
# 初期状態の描画
axes = [fig.add_subplot(M + 1, 2, k) for k in range(1, 3)]
axes[0].set_title('初期状態:観測データなし')
axes[1].set_title('初期事後分布')
plot_heatmap(axes[1], x_min, x_max, rv, x_seq, y_seq, pos)
# 逐次ベイズ学習のメインループ
result = []
x_seq_line = np.linspace(x_min, x_max, 100) # 回帰直線描画用
for j in range(M):
# 観測ベクトル H の構築(バイアス項と現在の x 値)
H = np.array([1.0, x[j]])
# パラメータ更新
pre_Gamma = Gamma
Gamma = pre_Gamma + beta * np.outer(H, H) # 精度行列更新
inv_Gamma = np.linalg.inv(Gamma) # 共分散行列計算
mu = inv_Gamma.dot(pre_Gamma.dot(mu) + beta * H * y[j]) # 平均更新
# 更新された分布の設定
rv = multivariate_normal(mu, inv_Gamma)
# 描画
axes = [fig.add_subplot(M + 1, 2, (j + 1) * 2 + k) for k in range(1, 3)]
# 左側:観測データと回帰直線
axes[0].set_title(f'ステップ {j+1}: 観測データ数 = {j+1}')
plot_data(axes[0], x_min, x_max, x[:j+1], y[:j+1], x_seq_line, mu)
# 右側:事後分布のヒートマップ
axes[1].set_title(f'事後分布(ステップ {j+1})')
plot_heatmap(axes[1], x_min, x_max, rv, x_seq, y_seq, pos)
# 結果の記録
result.append([j+1, mu[0], mu[1], c[0], c[1]])
plt.tight_layout()
plt.show()

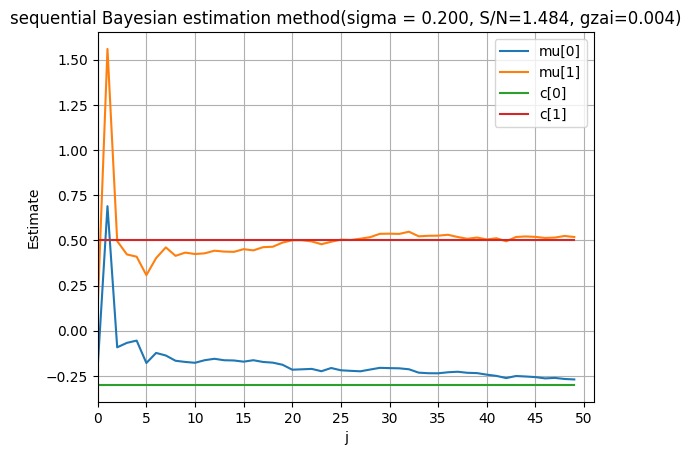
3.5 推定結果の分析
# 推定値の確認
df = DataFrame(data=result, columns=['j', 'μ[0]', 'μ[1]', 'c[0]', 'c[1]'])
# 最終推定結果の表示
print("=== 最終推定結果 ===")
print(f"真値: θ₀ = {c[0]:.3f}, θ₁ = {c[1]:.3f}")
print(f"推定値: θ₀ = {mu[0]:.3f}, θ₁ = {mu[1]:.3f}")
print(f"推定誤差: Δθ₀ = {abs(mu[0] - c[0]):.3f}, Δθ₁ = {abs(mu[1] - c[1]):.3f}")
# 推定値の時系列変化
df.plot(x='j', y=['μ[0]', 'μ[1]', 'c[0]', 'c[1]'], figsize=(12, 6))
plt.title(f'逐次ベイズ推定による収束過程 (σ = {sigma:.3f}, S/N = {np.std(c[0] + c[1] * x) / sigma:.3f}, ξ = {gzai:.3f})')
plt.xlabel('観測データ数 j')
plt.ylabel('パラメータ推定値')
plt.xticks(np.arange(0, M+1, M//10))
plt.xlim(0, M+1)
plt.grid(True, alpha=0.3)
plt.legend(['θ₀推定値', 'θ₁推定値', 'θ₀真値', 'θ₁真値'])
plt.show()
# 統計的な収束特性の分析
print("\n=== 収束特性の分析 ===")
final_10_percent = int(M * 0.9)
theta0_variance = np.var(df['μ[0]'].iloc[final_10_percent:])
theta1_variance = np.var(df['μ[1]'].iloc[final_10_percent:])
print(f"最終10%での推定値分散: Var(θ₀) = {theta0_variance:.6f}, Var(θ₁) = {theta1_variance:.6f}")
パラメータ感度分析
4.1 精度パラメータ β の影響
ノイズの標準偏差を変更して、精度パラメータ の影響を確認します。
# ノイズレベルを増加(σ = 0.8)
np.random.seed(0)
c = np.array([-0.3, 0.5])
sigma = 0.8 # ノイズ標準偏差を増加
alpha = 0.1
beta = 1.0 / (sigma ** 2) # β は小さくなる
gzai = alpha / beta
mu = np.zeros(2)
Gamma = alpha * np.identity(2)
inv_Gamma = np.linalg.inv(Gamma)
M = 50
# データ生成
e = np.random.normal(0, sigma, M)
x = np.random.uniform(-1.0, 1.0, M)
y = c[0] + c[1] * x + e
# 逐次ベイズ学習
result_beta = []
for j in range(M):
H = np.array([1.0, x[j]])
pre_Gamma = Gamma
Gamma = pre_Gamma + beta * np.outer(H, H)
inv_Gamma = np.linalg.inv(Gamma)
mu = inv_Gamma.dot(pre_Gamma.dot(mu) + beta * H * y[j])
result_beta.append([j+1, mu[0], mu[1], c[0], c[1]])
# 結果の可視化
df_beta = DataFrame(data=result_beta, columns=['j', 'μ[0]', 'μ[1]', 'c[0]', 'c[1]'])
df_beta.plot(x='j', y=['μ[0]', 'μ[1]', 'c[0]', 'c[1]'], figsize=(12, 6))
plt.title(f'高ノイズ環境での逐次ベイズ推定 (σ = {sigma:.3f}, S/N = {np.std(c[0] + c[1] * x) / sigma:.3f}, ξ = {gzai:.3f})')
plt.xlabel('観測データ数 j')
plt.ylabel('パラメータ推定値')
plt.xticks(np.arange(0, M+1, M//10))
plt.xlim(0, M+1)
plt.grid(True, alpha=0.3)
plt.legend(['θ₀推定値', 'θ₁推定値', 'θ₀真値', 'θ₁真値'])
plt.show()
print(f"高ノイズ環境(σ = {sigma}):")
print(f"β = {beta:.3f} (低精度)")
print(f"最終推定値: θ₀ = {mu[0]:.3f}, θ₁ = {mu[1]:.3f}")
print(f"推定誤差: Δθ₀ = {abs(mu[0] - c[0]):.3f}, Δθ₁ = {abs(mu[1] - c[1]):.3f}")
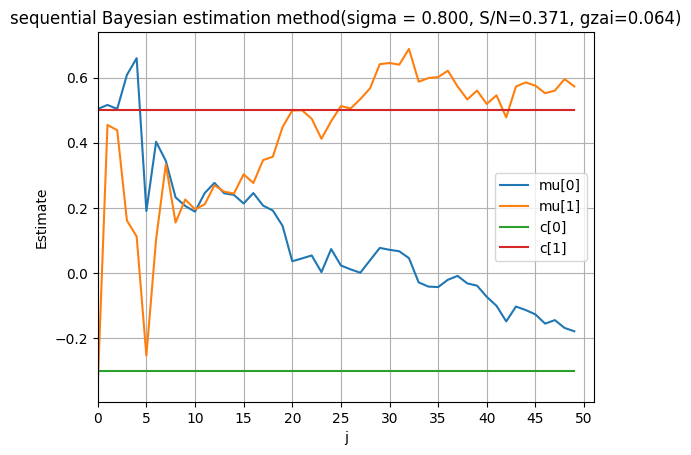
の関係から:
- が大きい → が小さい → 観測ノイズが大きい
- 観測分布の分散 が大きくなるため、推定性能が悪化
- 収束が遅く、最終的な推定精度も低下
これは理論的予想と一致する結果です。
4.2 事前精度パラメータ α の影響
事前分布の精度パラメータ の影響を確認します。
# 事前精度を増加(α = 0.8)
np.random.seed(0)
c = np.array([-0.3, 0.5])
sigma = 0.2
alpha = 0.8 # 事前分布精度を増加
beta = 1.0 / (sigma ** 2)
gzai = alpha / beta
mu = np.zeros(2)
Gamma = alpha * np.identity(2) # より高精度な事前分布
inv_Gamma = np.linalg.inv(Gamma)
M = 50
# データ生成
e = np.random.normal(0, sigma, M)
x = np.random.uniform(-1.0, 1.0, M)
y = c[0] + c[1] * x + e
# 逐次ベイズ学習
result_alpha = []
for j in range(M):
H = np.array([1.0, x[j]])
pre_Gamma = Gamma
Gamma = pre_Gamma + beta * np.outer(H, H)
inv_Gamma = np.linalg.inv(Gamma)
mu = inv_Gamma.dot(pre_Gamma.dot(mu) + beta * H * y[j])
result_alpha.append([j+1, mu[0], mu[1], c[0], c[1]])
# 結果の可視化
df_alpha = DataFrame(data=result_alpha, columns=['j', 'μ[0]', 'μ[1]', 'c[0]', 'c[1]'])
df_alpha.plot(x='j', y=['μ[0]', 'μ[1]', 'c[0]', 'c[1]'], figsize=(12, 6))
plt.title(f'高精度事前分布での逐次ベイズ推定 (σ = {sigma:.3f}, S/N = {np.std(c[0] + c[1] * x) / sigma:.3f}, ξ = {gzai:.3f})')
plt.xlabel('観測データ数 j')
plt.ylabel('パラメータ推定値')
plt.xticks(np.arange(0, M+1, M//10))
plt.xlim(0, M+1)
plt.grid(True, alpha=0.3)
plt.legend(['θ₀推定値', 'θ₁推定値', 'θ₀真値', 'θ₁真値'])
plt.show()
print(f"高精度事前分布環境(α = {alpha}):")
print(f"事前分布の分散が小さい → 事前情報への信頼度が高い")
print(f"最終推定値: θ₀ = {mu[0]:.3f}, θ₁ = {mu[1]:.3f}")
print(f"推定誤差: Δθ₀ = {abs(mu[0] - c[0]):.3f}, Δθ₁ = {abs(mu[1] - c[1]):.3f}")
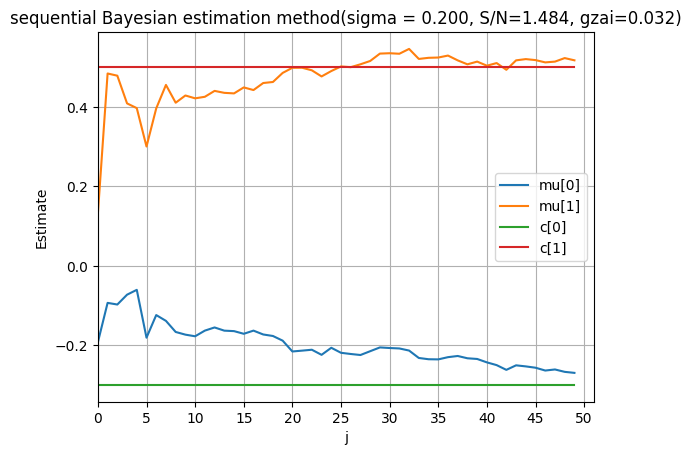
の増加により:
- 事前分布の分散 が小さくなる
- 事前情報に対する信頼度が高くなる
- より安定した推定が可能になり、収束が早くなる
- 少数のサンプルでも良好な推定性能を発揮
ただし、事前分布が真値から大きく外れている場合は、バイアスが生じる可能性があります。
4.3 S/N比の影響
信号対雑音比(S/N比)は推定性能の重要な指標です:
S/N比の解釈:
- S/N比が大きい:信号成分がノイズ成分より大きく、高精度な推定が可能
- S/N比が小さい:ノイズが支配的で、推定が困難
上記の実験結果から:
- 基本設定(σ = 0.2):S/N ≈ 2.5 → 良好な推定性能
- 高ノイズ(σ = 0.8):S/N ≈ 0.6 → 推定性能低下
これは解析的予想と一致する結果です。
理論的考察
ベイズ学習の利点
-
不確実性の定量化
- パラメータの分散を通じて推定の信頼性を評価
- 予測区間の計算が可能
-
逐次学習能力
- 新しいデータが得られるたびに効率的に更新
- オンライン学習に適している
-
事前知識の組み込み
- 専門知識や過去の経験を事前分布に反映
- 少数のサンプルでも安定した推定
-
正則化効果
- 事前分布が自然な正則化として機能
- 過学習を防ぐ効果
計算効率性
逐次ベイズ学習の更新式:
精度行列の更新:
平均の更新:
これにより、すべてのデータを再処理することなく効率的に更新できます。
理論的保証
- 漸近的一致性:データ数が増加すると真値に収束
- 最適性:平均二乗誤差最小の推定値
- 共役性:正規分布の組み合わせにより解析的解が得られる
実用的な応用
適用分野
- 時系列予測:経済データ、センサーデータの予測
- 制御システム:システム同定、適応制御
- 機械学習:ベイジアンニューラルネットワーク
- 信号処理:カルマンフィルタ、粒子フィルタ
実装のポイント
-
数値的安定性
- 精度行列の逆行列計算に注意
- Cholesky分解の活用を検討
-
事前分布の設定
- ドメイン知識の活用
- 非情報事前分布の使用
-
収束判定
- パラメータ変化量の監視
- 対数尤度の変化を確認
まとめ
ベイズ推定による線形回帰は、以下の特徴を持つ強力な手法です:
主要な特徴
- 確率的解釈:パラメータを確率変数として扱い、不確実性を定量化
- 逐次更新:新しいデータに対して効率的な更新が可能
- 事前知識の活用:既知の情報を自然に組み込める
- 理論的保証:最適性と一致性が数学的に保証される
パラメータの影響
- (事前精度):大きいほど事前情報への信頼度が高く、安定した推定
- (観測精度):大きいほど観測の信頼度が高く、高精度な推定
- S/N比:大きいほど信号成分が支配的で、良好な推定性能
実用的価値
現代の機械学習において、ベイズ推定は不確実性の定量化という重要な役割を果たしています。深層学習においても、ベイジアンニューラルネットワークやVariational Autoencoderなど、様々な応用が存在します。
本手法は、データサイエンスの基礎として、また実用的な予測手法として、幅広い分野で活用されている重要な技術です。
- ベイジアン回帰の拡張:非線形回帰、ガウス過程回帰
- 変分ベイズ:複雑なモデルへの近似的ベイズ推論
- マルコフ連鎖モンテカルロ法:解析的に扱えないモデルへの適用
- ベイジアンニューラルネットワーク:深層学習への応用