Introduction to Model Predictive Control
Model Predictive Control (MPC), also known as Receding Horizon Control, is an advanced control strategy that solves an optimal control problem over a finite prediction horizon at each sampling time. This document provides a comprehensive introduction to MPC fundamentals and implementation.
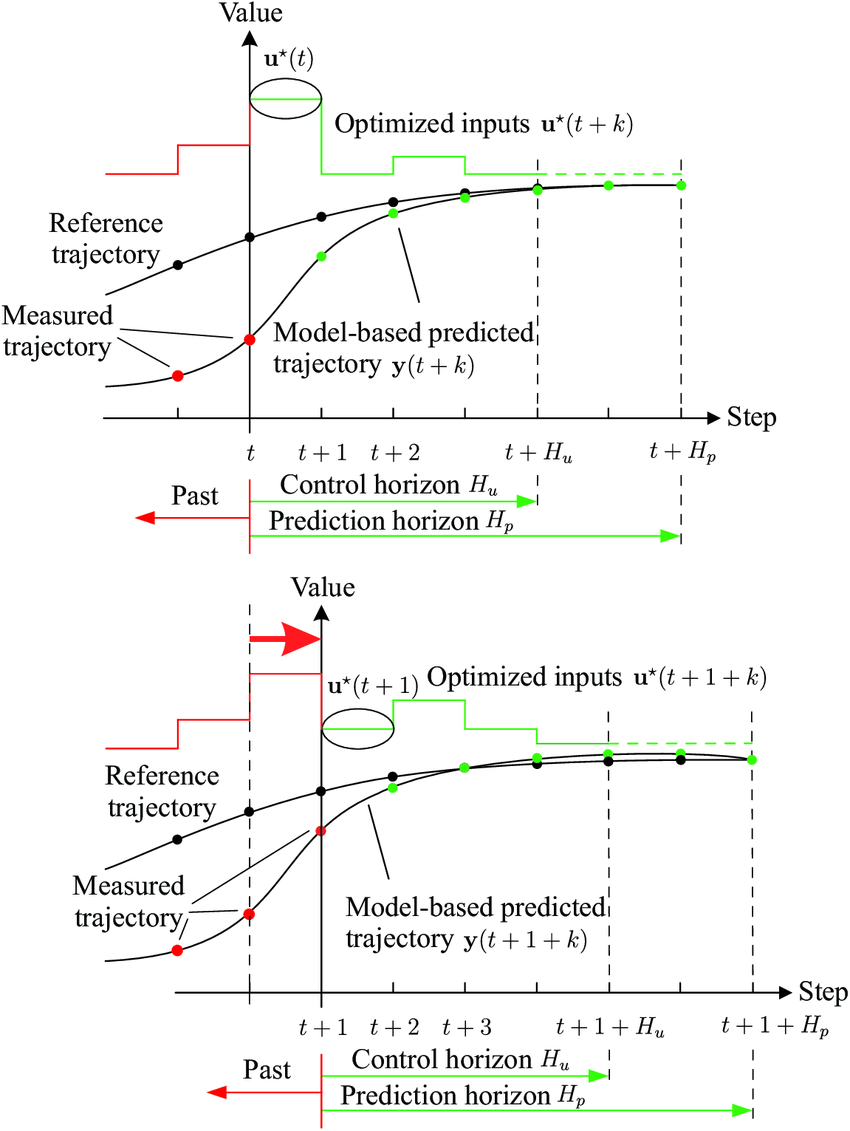
MPC Overview
Core Concept
MPC is based on the principle of receding horizon optimization:
- Predict future system behavior over a prediction horizon
- Optimize control actions to minimize a cost function
- Apply only the first optimal control action
- Repeat the process at the next time step with updated measurements
This approach provides several advantages:
- Constraint handling: Natural incorporation of system constraints
- Multivariable control: Systematic handling of MIMO systems
- Preview capabilities: Ability to utilize future reference information
- Robustness: Online optimization adapts to disturbances and uncertainties
The optimization horizon moves forward in time at each sampling instant, always maintaining the same horizon length. This creates a "receding" effect where the future optimization window slides forward continuously.
Mathematical Formulation
System Model
Consider a discrete-time nonlinear system:
Where:
- : state vector at time
- : control input vector at time
- : system dynamics (potentially nonlinear)
Performance Function
The MPC optimization problem is formulated as:
Where:
- : prediction horizon (number of future time steps to consider)
- : control horizon (number of control moves to optimize)
- : desired reference trajectory
- : terminal cost function
- : stage cost function
Commonly, we set for simplicity, although different horizons can be used based on specific requirements:
- : Control becomes constant after steps
- : Full control authority over prediction horizon
MPC Algorithm Steps
At each time step , MPC performs:
Step 1: State Measurement/Estimation
- Obtain current state (measured or estimated)
Step 2: Optimization
- Solve for optimal control sequence:
- Predict future states:
Step 3: Control Application
- Apply only the first control action:
Step 4: Horizon Shift
- Move to time and repeat the process
Notation Convention
- : Control action calculated at time to be applied at time
- : State predicted at time for time
- : Conditional notation indicating "given information at time"
Quadratic Programming Foundation
Why Quadratic Programming?
For linear systems with quadratic cost functions, MPC reduces to a Quadratic Programming (QP) problem, which can be solved efficiently using well-established numerical methods.
General QP Formulation
A quadratic program has the form:
Minimize:
Subject to:
Where:
- : optimization variables (control sequence in MPC)
- : positive semi-definite Hessian matrix
- : linear term vector
- : constraint matrices
- : constraint vectors
- : variable bounds
Case A: Unconstrained Optimization
When there are no constraints and is positive definite:
Optimality condition:
Analytical solution:
Second-order condition:
Case B: Equality Constraints
For problems with equality constraints , we use the Lagrange multiplier method.
Lagrangian function:
Optimality conditions:
System of equations:
Solution (if inverse exists):
Case C: Inequality Constraints
For problems with inequality constraints, analytical solutions are generally not available. Numerical methods are required:
Common solution methods:
- Interior-point methods: Efficient for large problems
- Active-set methods: Good for small to medium problems
- Gradient-based methods: Simple but potentially slow convergence
Implementation Tools
MATLAB Implementation
MATLAB provides built-in optimization tools for QP problems:
% Quadratic programming solver
x = quadprog(Q, R, A, b, Aeq, beq, xL, xU);
% With options for algorithm selection
options = optimoptions('quadprog', 'Algorithm', 'interior-point');
x = quadprog(Q, R, A, b, Aeq, beq, xL, xU, [], options);
Key parameters:
Q, R: Objective function matricesA, b: Inequality constraint matricesAeq, beq: Equality constraint matricesxL, xU: Variable bounds
CasADi Framework
CasADi is an open-source tool for nonlinear optimization supporting multiple platforms:
Python example:
import casadi as ca
# Define optimization variables
x = ca.MX.sym('x', n)
# Define objective function
J = 0.5 * ca.mtimes([x.T, Q, x]) + ca.mtimes(R.T, x)
# Define constraints
g = [] # constraint expressions
lbg = [] # lower bounds
ubg = [] # upper bounds
# Create optimization problem
nlp = {'x': x, 'f': J, 'g': ca.vertcat(*g)}
solver = ca.nlpsol('solver', 'ipopt', nlp)
# Solve
sol = solver(x0=x_init, lbg=lbg, ubg=ubg, lbx=x_L, ubx=x_U)
x_opt = sol['x']
MATLAB example:
import casadi.*
% Define optimization variables
x = MX.sym('x', n);
% Define objective function
J = 0.5 * x' * Q * x + R' * x;
% Define constraints
g = []; % Add constraints as needed
% Create optimization problem
nlp = struct('x', x, 'f', J, 'g', vertcat(g));
solver = nlpsol('solver', 'ipopt', nlp);
% Solve
sol = solver('x0', x_init, 'lbg', lbg, 'ubg', ubg, ...
'lbx', x_L, 'ubx', x_U);
x_opt = full(sol.x);
MPC Design Considerations
1. Horizon Selection
Prediction horizon ():
- Longer horizons: Better performance, higher computational cost
- Shorter horizons: Faster computation, potentially degraded performance
- Rule of thumb: Choose to cover system settling time
Control horizon ():
- : Reduced computational burden, control becomes constant
- : Full control flexibility, higher computational cost
2. Cost Function Design
State penalties:
- Weight matrices should reflect relative importance of states
- Larger weights → tighter regulation of corresponding states
Control penalties:
- Weight matrices balance control effort vs. performance
- Larger weights → more conservative control action
Terminal cost:
- Function ensures stability for finite horizons
- Often chosen as infinite-horizon LQR cost
3. Constraint Formulation
Input constraints:
State constraints:
Slew rate constraints:
Advantages and Limitations
Advantages
- Natural constraint handling: Incorporates physical limitations directly
- Multivariable capability: Systematic approach for MIMO systems
- Predictive nature: Uses model to anticipate future behavior
- Flexibility: Accommodates time-varying references and constraints
- Online optimization: Adapts to disturbances and model uncertainties
Limitations
- Computational requirements: Online optimization can be demanding
- Model dependency: Performance relies on model accuracy
- Parameter tuning: Requires careful selection of horizons and weights
- Feasibility issues: Constraints may lead to infeasible problems
- Stability guarantees: Require careful design for finite horizons
Applications
Industrial Applications
- Chemical processes: Refineries, petrochemical plants
- Power systems: Grid control, renewable energy integration
- Automotive: Engine control, autonomous driving
- Aerospace: Flight control, trajectory optimization
- Manufacturing: Robotics, process optimization
Academic Research Areas
- Robust MPC: Handling model uncertainties
- Stochastic MPC: Dealing with random disturbances
- Economic MPC: Optimizing economic objectives
- Distributed MPC: Large-scale system control
- Learning-based MPC: Integration with machine learning
Summary
Model Predictive Control represents a paradigm shift in control system design:
- From reactive to predictive: Uses model to anticipate future behavior
- From unconstrained to constrained: Natural incorporation of physical limitations
- From SISO to MIMO: Systematic handling of multivariable systems
- From fixed to adaptive: Online optimization enables real-time adaptation
The combination of prediction, optimization, and constraint handling makes MPC particularly suitable for complex, multivariable systems with operating constraints.
Next Steps
To fully understand MPC implementation:
- Study unconstrained MPC: Linear systems with quadratic costs
- Explore constraint handling: QP formulation and solution methods
- Analyze stability: Terminal constraints and costs
- Implement examples: Simple systems to understand behavior
- Advanced topics: Robust MPC, nonlinear MPC, economic MPC
References
- Rawlings, J. B., Mayne, D. Q., & Diehl, M. (2017). Model Predictive Control: Theory, Computation, and Design (2nd ed.). Nob Hill Publishing.
- Rakovic, S. V., & Levine, W. S. (2018). Handbook of Model Predictive Control. Birkhäuser.
- Camacho, E. F., & Alba, C. B. (2013). Model Predictive Control (2nd ed.). Springer-Verlag.
- CH02-QuadraticProgramming.pdf (Berkeley)
- What Is Model Predictive Control? - MATLAB
- CasADi - A symbolic framework for automatic differentiation